
Contents
Evaluating Explanation Without Ground Truth in Interpretable Machine Learning
arXiv’19, cite:24, PDF link: https://arxiv.org/pdf/1907.06831.pdf
F Yang, Texas A&M University(美国,得州农工大学)
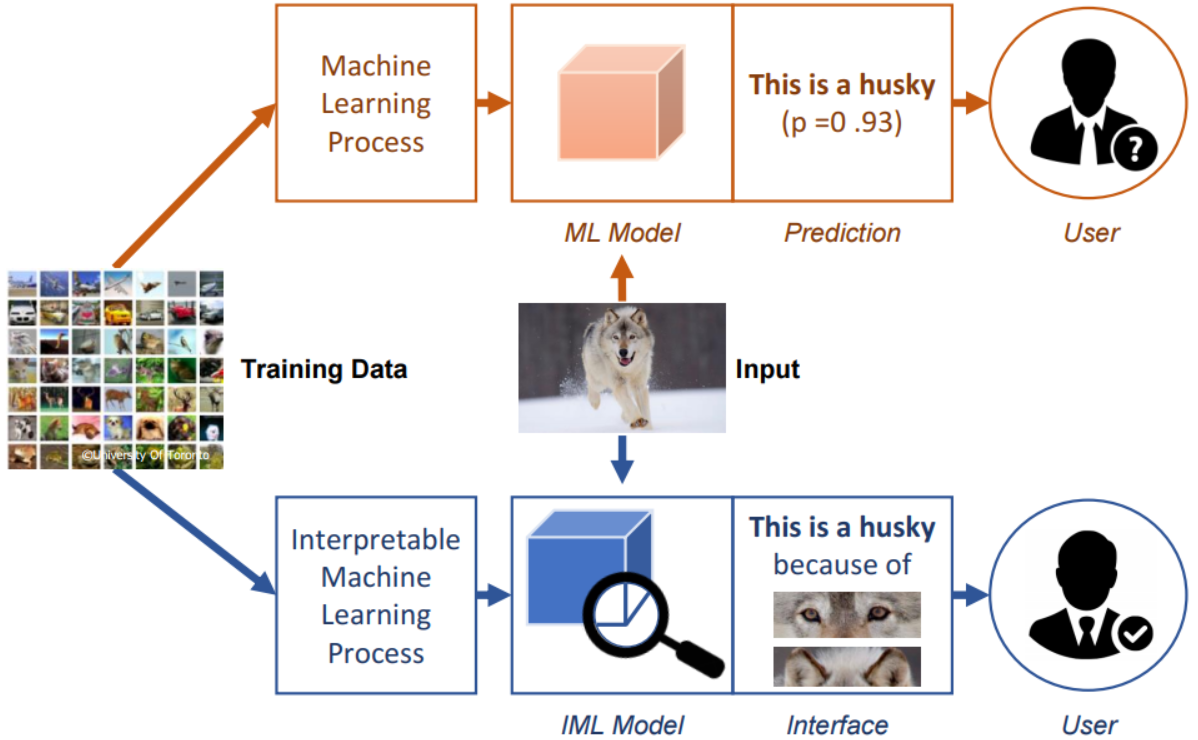
Interpretable Machine Learning (IML)
- Aiming to help humans understand the machine learning decisions.
- IML model is capable of providing specific reasons for particular machine decisions, while ML model may simply provide the prediction results with probability scores.
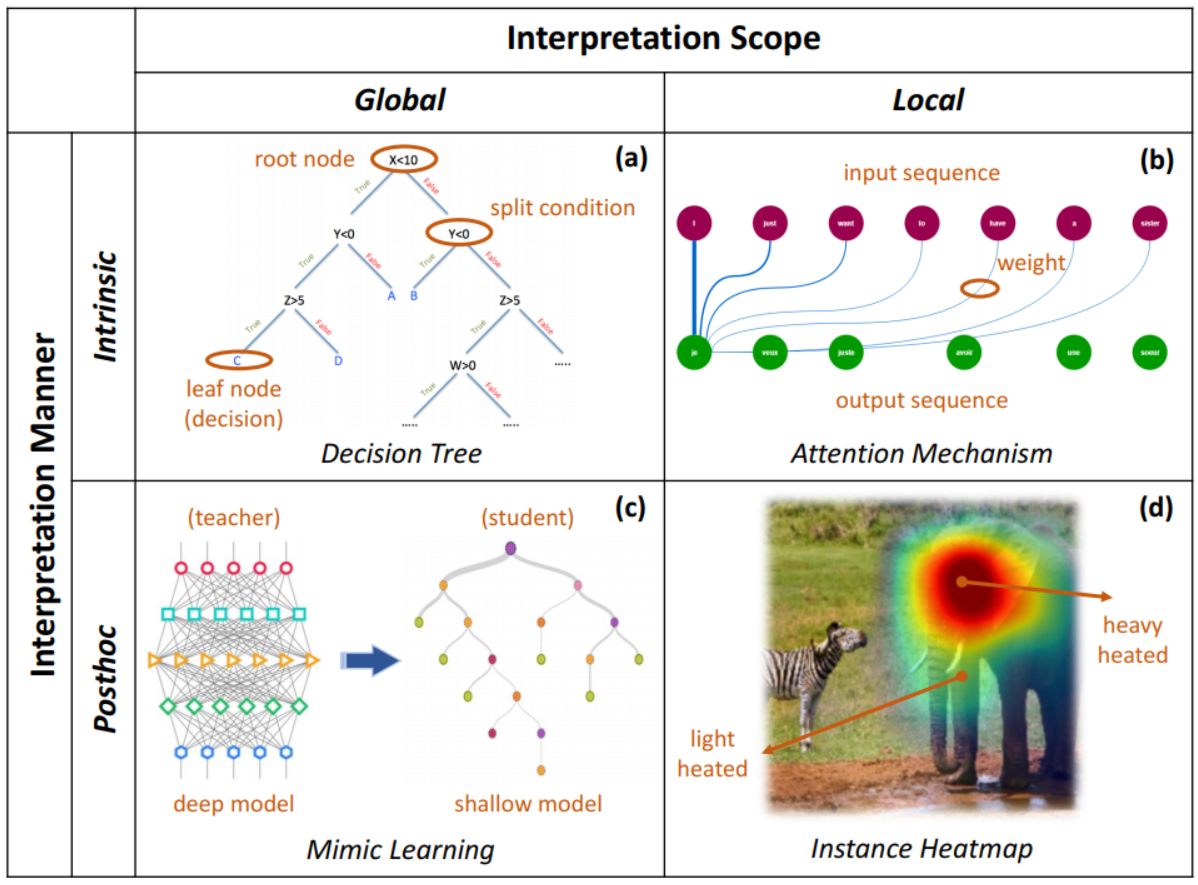
A two-dimensional categorization
- Scope dimension
- global: the overall working mechanism of models -> interpret structures or parameters
- local: the particular model behavior for individual instance -> analyze specific decisions
- Manner dimension
- intrinsic: achieved by self-interpretable models
- post-hoc (also written as posthoc): requires another independent interpretation model or technique
General Properties of Explanation
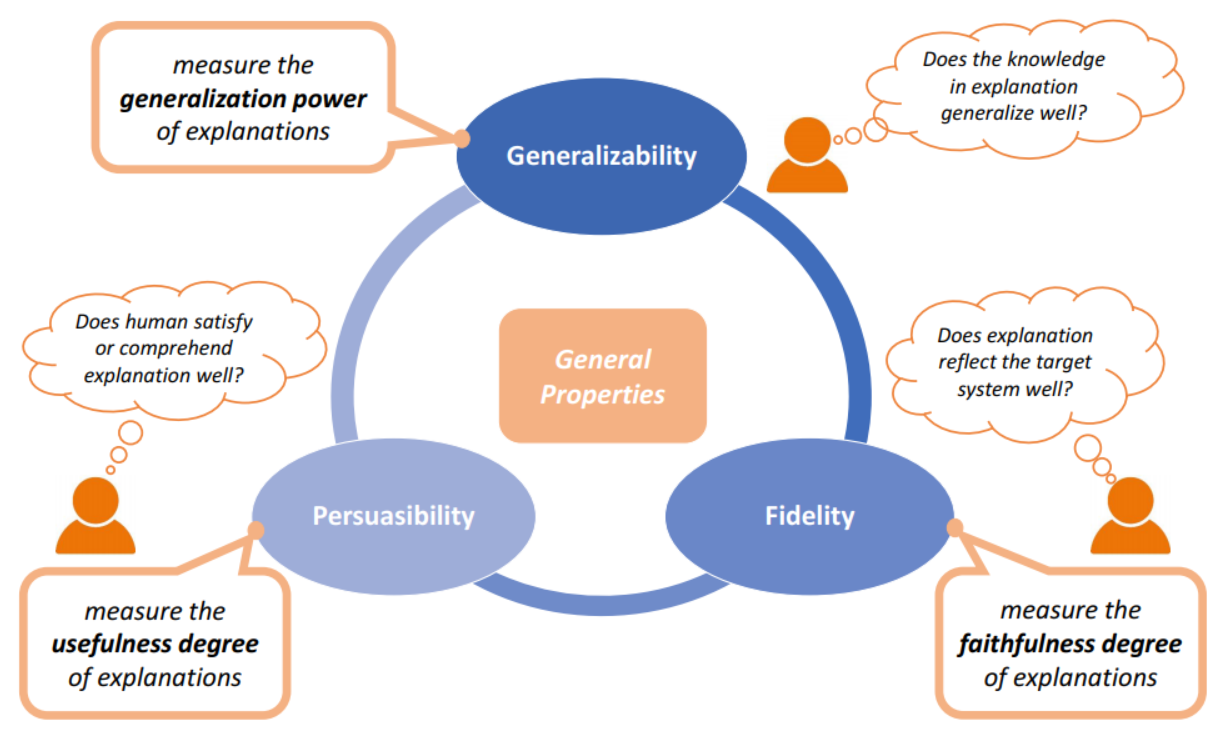
Generalizability (概括性)
- intrinsic-global: apply those explanations on test data; somewhat equivalent to the model evaluation.
- Metric: 由于等价于原模型的评估,使用的就是传统的 accuracy 和 F1-score 等
- Conventional examples: generalized linear model (with informative coefficients) , decision tree (with structured branches) , K-nearest neighbors (with significant instances) and rule-based systems (with discriminative patterns)
- posthoc-global: similar to the intrinsic-global ones; the major difference lies in the fact that the explanations on test data are not directly associated with the target system, but are closely related to the interpretable proxies extracted or learned from the target.
- Metric: AUC score, …
- Examples: knowledge distillation (知识蒸馏) -focus-> derive an interpretable proxy out of the black-box neural model; e.g., Gradient Boosting Trees
Fidelity (保真度): 对于 intrinsic 类别的解释,可认为是完全保真的 completely accordance between model and explanation -> full fidelity
- posthoc-global: difference in prediction performance between the interpretable proxy and the target system
- Example: difference between teacher and student model
- posthoc-local: prediction variation after the adversarial changes made according to the generated explanation
- Philosophy: modifications made in accordance with the generated explanation to the input instances bring about significant differences to model prediction (if the explanation is faithful to the target system).
- Example: mask the attributing regions in images; ablation and perturbation operations on text
Persuasibility (可说服度): 常用于评价 local 的解释
- uncontentious tasks: 如目标检测等无争议的任务(typically keep consistent across different groups of user and one particular task),可以使用与人工注解比较的方法来评估
- Examples
- [CV: annotation] bounding box -metric-> Intersection over Union (IoU, also Jacarrd Index), semantic segmentation (标注出图像中每个像素所属的对象类别) -metric-> pixel-level difference
- [NLP: rationale -> subset of features highlighted by annotators]
- Examples
- complicated tasks: employing users for human studies; mental mode, human-machine performance, user satisfaction, user trust
- Example: human response time, decision accuracy
Other Properties
Robustness: adversarial perturbations; how similar the explanations are for similar examples
Capability: search-based methodologies -(recommender system)-> explainability precision/recall
-
Example: 推荐系统中,原系统和IML系统输出都是集合;EP(explainability precision)指的是 Top-K 推荐中可以解释的项目占推荐数量的的比例,ER(explainability recall)指的是 Top-K 推荐中可解释的项目在所有可解释项目中占的比例,即两集合的交集元素个数分别与两个集合元素个数求比值。MEP 和 MER 分别是所有用户的EP和ER的平均值。
- \(MEP=\sum_{u\in \mathcal{U}}\frac{\vert \mathcal{I_{u}^{ir}} \vert}{\vert \mathcal{I_u^r} \vert} / \vert \mathcal{U} \vert\), \(MER=\sum_{u\in \mathcal{U}}\frac{\vert \mathcal{I_{u}^{ir}} \vert}{\vert \mathcal{I_u^i} \vert} / \vert \mathcal{U} \vert\)
Towards Interpretation of Recommender Systems with Sorted Explanation Paths 论文中叫 Applicability,制定这一标准是因为有的解释方法会返回 NULL;评价被推荐的项目中可以被模型解释的项目的占比(不考虑解释的质量)
Certainty: discrepancy in prediction confidence of the IML system between one category and the others
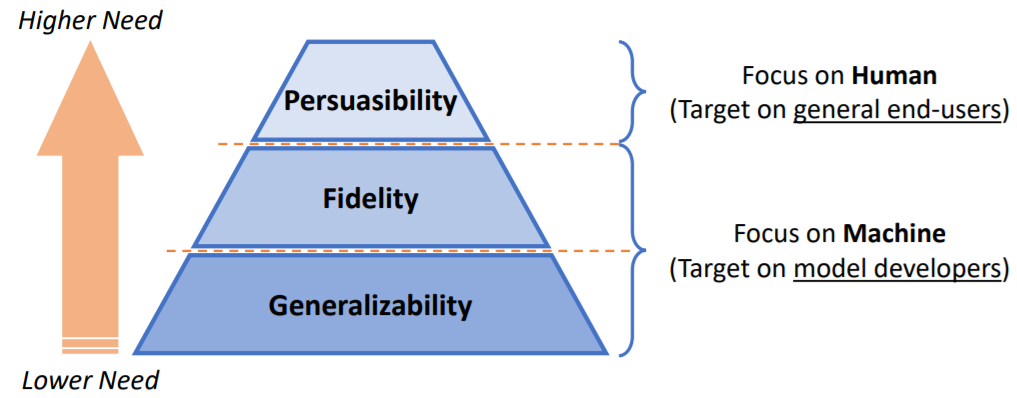
Unified Framework for Evaluation
-
Generalizability -> reflect the true knowledge for particular tasks? -> the precondition for human users to make accurate decisions with the generated explanations
-
Fidelity -> explanation relevance -> trust the IML system or not?
-
Persuasibility -> directly bridge the gap between human users and machine explanations -> tangible impacts
Each tier should have a consistent pipeline with a fixed set of data, user, and metrics correspondingly.
The overall evaluation results can be further derived through an ensemble way, e.g., weighted sum.
Open Problems for Benchmark
-
Generalizability for local explanations
- Two challenges: local explanations (1) cannot be easily organized into valid prediction models; (2) simply contain the partial knowledge learned by the target IML system.
- Possible solutions
- (1) build an approximated local classifier and then assess the generalizability by specifying test instances (适用于intrinsic,如固定local的attention值,指定近似的测试样本来看分类结果);
- (2) employ local explanations, together with human simulated/augmented data, to train a separate classifier (适用于posthoc,增加人为数据单独训练一个分类器,将原分类任务缩减为只包含local knowledge的分类).
-
Fidelity for posthoc explanations
-
Problem: it might not be the case that faithful explanations are always the good ones that human user prefer.
fidelity主要衡量explanation和原模型的一致性,而原模型的输出可能是不好的/错误的
-
Possible solutions: utilize the model performance to guide the measurement of posthoc explanation fidelity.
-
-
Persuasibility for global explanations
-
Challenge: global explanations in real applications are very sophisticated -> hard to make annotations or select appropriate users for studies
-
Possible solutions
-
use some simplified or proxy tasks to simulate the original one -> non-trivial efforts on task abstraction
Towards A Rigorous Science of Interpretable Machine Learning:
3.2 Human-grounded Metrics: Real humans, simplified tasks -example (forward simulation/prediction task: common intrusion-detection test in topic models)->
ask the human to find the difference between the model’s true output and some corrupted output as a way to determine whether the human has correctly understood what the model’s true output is.
-
simplify the explanations shown to users -> sacrifices the comprehensiveness
-
-