High-level idea


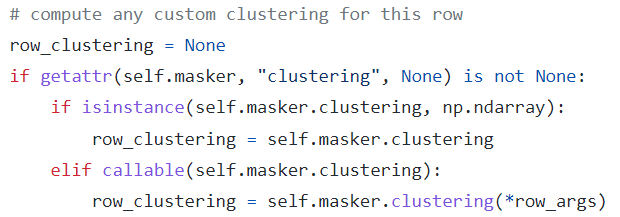
Explainers在explain_row函数中,依据self.masker的clustering属性生成单个样本的masks,该属性可以是固定的np.ndarray,也可以是callable的(每个样本有不同的簇划分方式)。
Partition explainer 使用 make_mask(self._clustering) 生成 self._mask_matrix,传入owen函数


These benchmark notebooks compare different types of explainers across a variety of metrics. They are all generated from Jupyter notebooks available on GitHub.
# use an independent masker
masker = shap.maskers.Independent(X_train)
pmasker = shap.maskers.Partition(X_train)
# build the explainers
explainers = [
("Permutation", shap.explainers.Permutation(model.predict, masker)),
("Permutation part.", shap.explainers.Permutation(model.predict, pmasker)),
("Partition", shap.explainers.Partition(model.predict, pmasker)),
("Tree", shap.explainers.Tree(model, masker)),
("Tree approx.", shap.explainers.Tree(model, masker, approximate=True)),
("Exact", shap.explainers.Exact(model.predict, masker)),
("Random", shap.explainers.other.Random(model.predict, masker))
]
# shap/maskers/__init__.py
from ._masker import Masker
from ._tabular import Independent, Partition, Impute
from ._image import Image
from ._text import Text
from ._fixed import Fixed
from ._composite import Composite
from ._fixed_composite import FixedComposite
from ._output_composite import OutputComposite
The two types of masker used during building the explainers:
Independent masks out tabular features by integrating over the given background dataset.Partition Unlike Independent, Partition respects a hierarchial structure of the data.
clustering:string (distance metric to use for creating the clustering of the features) or numpy.ndarray (the clustering of the features).The following two types of masker are used during benchmarking:
Composite merges several maskers for different inputs together into a single composite masker.Fixed leaves the input unchanged during masking, and is used for things like scoring labels.