Contents
Semi-Supervised Graph Classification: A Hierarchical Graph Perspective

研究问题
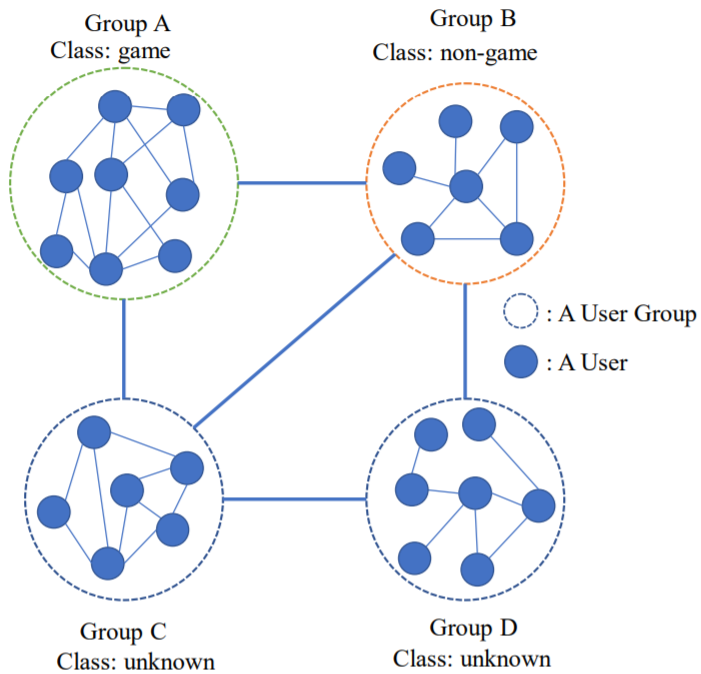
层次图上的半监督(图)节点分类。以下图为例,社交网络表示为一个“层次图”,其上的节点(用户组A,B,C,D)也是“图实例”;在每个表示用户组的图实例中,各节点表示一个用户,具有年龄、性别等属性;在(层次图、图实例)结构一定,已知部分(用户组)节点标签的情况下,对未知节点(C,D)进行分类。
解决方案
两个挑战
- 层次图对于分类器而言是一种复杂的输入结构
- 在真实数据中标签往往是稀缺的
方案思路
-
两个分类器(定义disagreement loss保证两个分类器结果的一致性)
- IC: instance-level,生成每个instance的
graph embedding、属于各类别的概率 - HC: hierarchical graph level,每个instance
属于各类别的概率
- IC: instance-level,生成每个instance的
-
半监督学习SEmi-supervised grAph cLassification(迭代的算法架构,轮流更新IC/HC)
两种迭代更新方法
- SEAL-CI: Cautious Iteration,每一轮HC预测后选出预测标签置信度较高的子集扩充训练集
- SEAL-AI: Active-learning,每次迭代时选出最具信息量的图实例做人工标注
损失函数
\[min\zeta(G_l)+\xi(G_u)\]-
减小有监督(labeled)样本的分类损失:IC和HC的交叉熵之和
\[\zeta(G_l)=\sum_{g_l\in{G_l}}(L(y_i,\psi_i)+L(y_i,\gamma_i))\] -
减小无监督(ublabeled)样本两个分类器之间的判别距离:KL散度 \(D_{KL}(P\vert\vert Q)=\sum_jP_jlog(\frac{P_j}{Q_j})\)
\[\xi(G_u)=\sum_{g_l\in{G_l}}D_{KL}(\gamma_i \vert \vert\psi_i)\]
分类器设计
IC: 生成Embedding
self-attetion graph embedding (SAGE):两层图卷积+(graph-level readout)attention机制
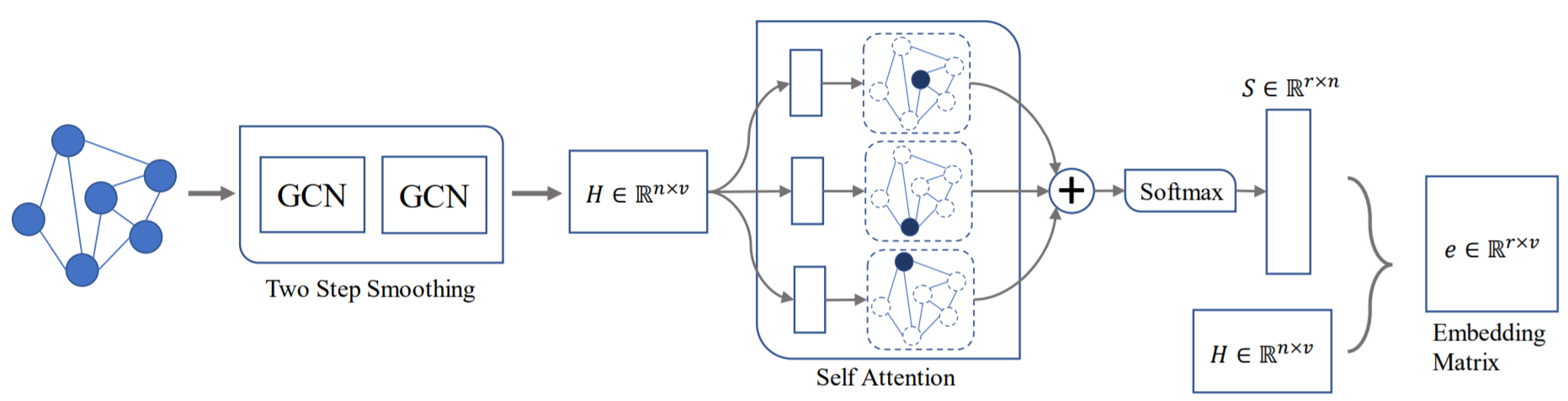
- 增加了损失项 \(\vert\vert SS^T-I_r \vert\vert _F^2\),惩罚attention矩阵将各节点视为类似重要的情况。其中 \(\vert\vert \cdot \vert\vert _F\) 表示矩阵的佛罗贝尼乌斯范数(Frobenius norm),即各元素的平方和开根号。
HC: 传统的节点分类任务
将每个图实例视为节点,输入邻接矩阵、节点特征(embedding)。使用两层GCN。
迭代模型
损失函数包含组合项和连续项;其中,有监督损失中的HC分类器损失依赖于IC的embedding结果;使得该优化问题非凸。因此使用迭代算法交替减小IC和HC分类器的有监督损失,通过在下轮迭代时信任HC预测结果的子集来减小分歧损失。
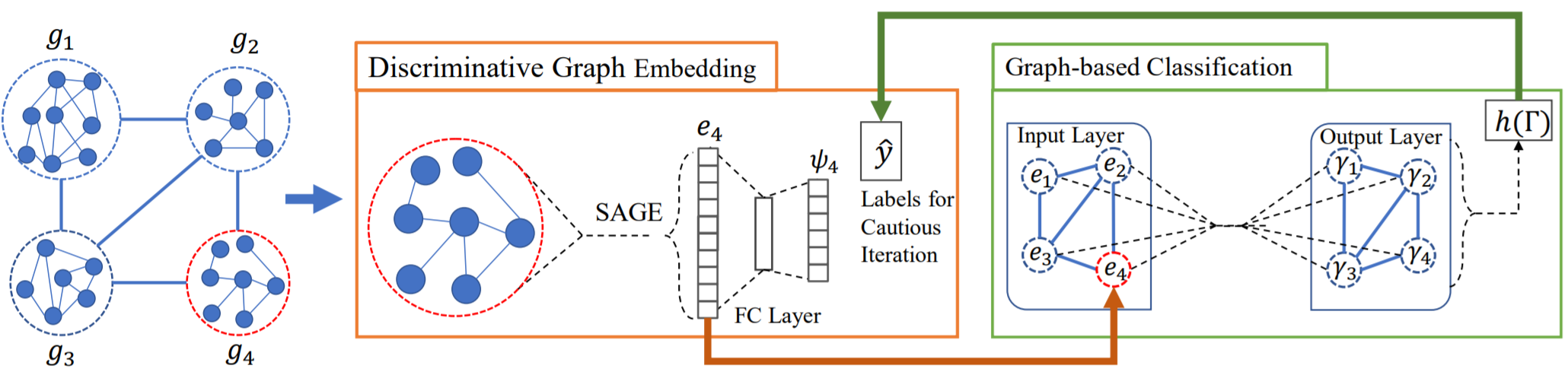
在\(t\)轮迭代时,IC生成所有节点的embedding \(E^t\),喂入HC,得到预测结果 \(\Gamma^t\),利用 \(\Gamma^t\) 更新IC的参数,生成 \(E^{t+1}\)…
Q: 如何利用\(\Gamma^t\) ?【算法Line 6】
-
SEAL-CI
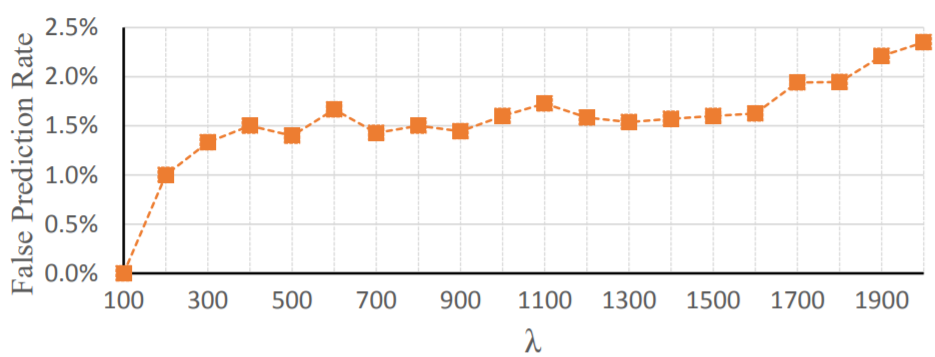
在\(t\)轮迭代时,从未标注样本中选择\(t\lambda\)个最”自信”的预测结果加入labeled样本,直到所有未标注样本被用完;
\(h(\lambda,\Gamma)=top(max_{\gamma\in{\Gamma}}\gamma, \lambda)\),其中函数\(top(\cdot, \lambda)\)表示选取前\(\lambda\)个示例。

为了提升效率,使用微调(fine-tune, not re-train)的方法更新IC.
没用到disagreement loss???还有循环中t未更新= =
-
SEAL-AI
\(G_{tmp}\)为一个使disagreement loss下降最快的样本集合。

其中 \(B\) 表示标注样本的预算开销。
复杂度分析
以SEAL-CI模型的一轮迭代为例,复杂度\(O(E_1\phi(L+U)+E_2rv)\)。与图实例的个数、边数,层次图的边数呈线性关系。
- 更新IC:所有图实例的GCN卷积,\(O(E_1\phi(L+U))\)
- 更新HC:层次图的GCN卷积,\(O(E_2rv)\)
- 候补图实例选择:未标注图实例预测结果的比较,\(O(L+U)\) ???
实验评估
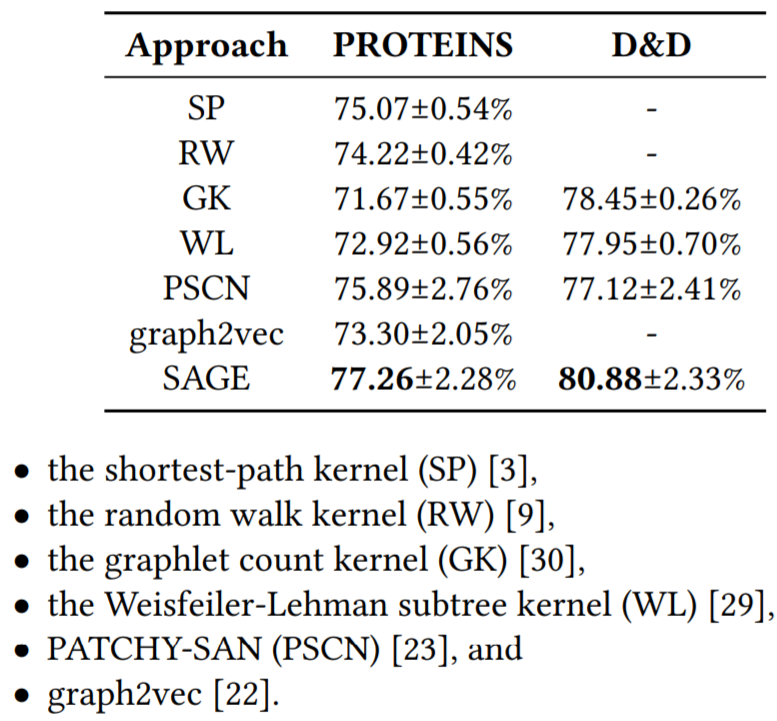
图嵌入算法(SAGE)
在PROTEINS和D&D数据集(判断蛋白质是不是酶)上,与6个baseline(前四种核方法与PSCN论文中的实验设置相同)比较,准确率如下:
SEAL-C/AI模型
-
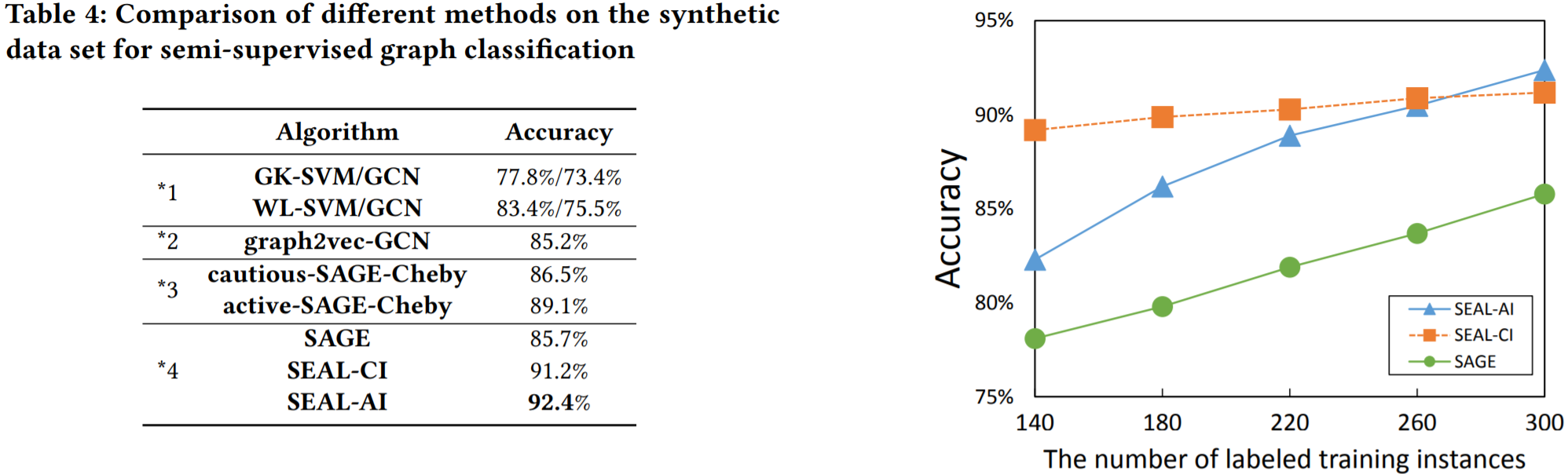
合成数据集:层次图结构来自Cora数据集,是包含2708个(论文)节点的引用网络;该数据集有7个类别的节点,每类使用不同的图生成算法来生成图实例。
7个图生成算法:Watts-Strogatz [32], Tree graph, Erdős-Rényi [8], Barbell [13], Bipartite graph, Baraba´siAlbert graph [2] and Path graph
-
QQ:37,836个用户组,共18,422,331个用户,每个用户有7个属性(注册天数,过去90天最活跃地区的代码,好友数,过去30天的活跃天数、登录次数、发送消息的条数、在用户组内发送消息的条数);用户组中,有1,773个标记为“game”,剩余为“non-game”。
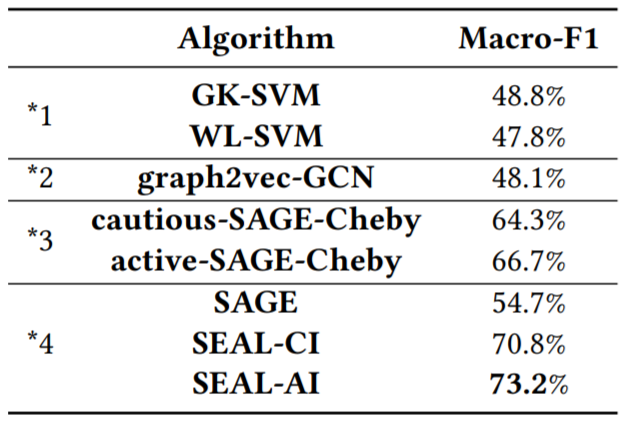
为什么SEAL-AL优于SEAL-CL?(随着迭代次数增加,SEAL-CL引入的新标签中不准确的增加)