
Contents
论文 DeepReflect: Discovering Malicious Functionality through Binary Reconstruction 被 USENIX Security ‘21 (Fall) 录用,来自佐治亚理工的 Wenke Lee 团队:

源码地址:https://github.com/evandowning/deepreflect
Motivation:恶意应用分析师的故事
Molly 是一名恶意应用分析师,她每天的主要任务就是理解恶意样本并给出技术报告。当拿到一个恶意样本时,Molly 有着一套如 图1 所示的工作流程,她首先将样本上传到 VirusTotal 等平台扫描,如果是一个已被恶意样本库收录的应用,她就可以轻松地结束本次工作。但这样的好事并不多见,因为待分析的往往是公司恶检系统的漏网之鱼。接着,她选择使用定制的沙箱来运行样本,以动态分析应用的恶意行为,但狡猾的样本采用了沙箱逃逸技术(检测到沙箱环境时则不执行部分代码)。于是,她又使用了一些内部工具,企图哄骗应用去执行隐藏的行为,却都无济于事。无奈之下,她只能将应用解包(脱壳)后做静态分析。
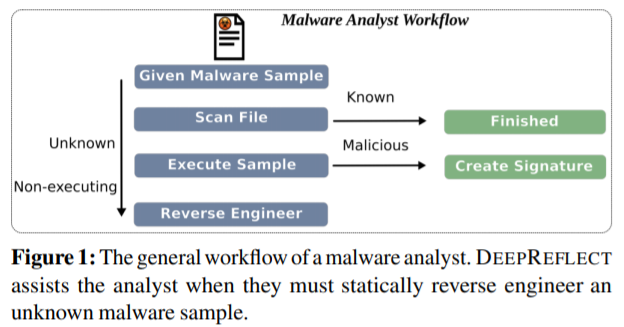
Molly 使用 IDA Pro(或 BinaryNinja)打开反编译后的二进制文件,数以千计的函数扑面而来,她尝试了各种静态签名检测工具来识别特定的恶意组件,仍未获得什么有用的信息。因此,她必须一个个地检查这些函数并理解它们的行为,具体的做法可能有:通过调用的 API 和存在的字符串过滤函数,通过调试来验证观察到的行为。在注解了应用行为后,她将一些如失陷标示(IOCs)、静态签名等的基本信息写入技术报告,并交给她的上级。
Indicators of compromise (IOCs) are “pieces of forensic data, such as data foumorend in system log entries or files, that identify potentially malicious activity on a system or network.”
设计目标
对于每一个恶意样本,Molly 都需要付出重复的劳力成本,使得这项工作冗余又耗时。本文的 DeepReflect 设计了两种功能减轻恶意应用分析师的工作:(1)定位:缩小需要检查的函数的范围,从上千个到包含了最有可能是恶意代码的子集;(2)标注:找出已知的较为相似的函数,给出标签。
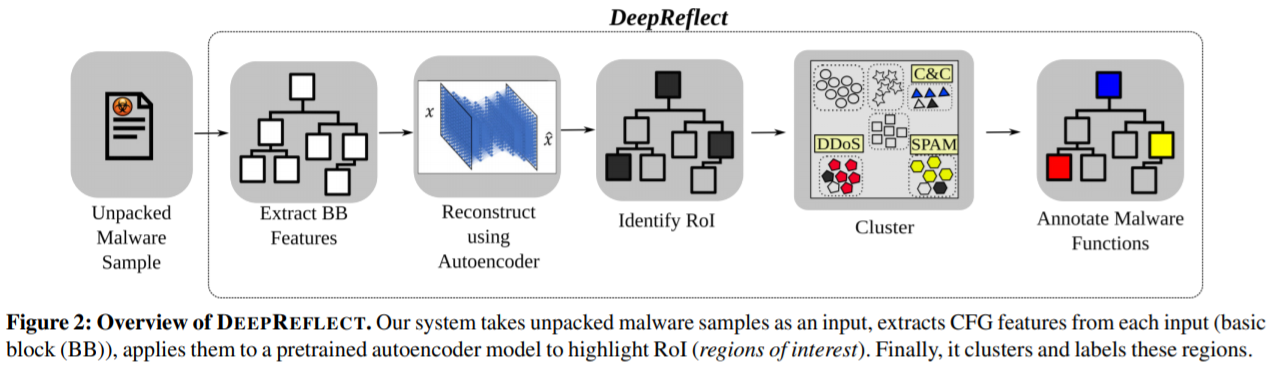
DeepReflect 解决方案
实现“定位”和“标注”
- 将二进制文件表示为特征矩阵,对应每个basic block(BB)的特征向量,使用 AutoEncoder 在良性应用上做无监督学习;对于任意输入样本,重构误差较大的特征向量对应的基本块(RoI)可能包含恶意代码;
- 将函数表示为其包含的 ROI(regions of interest) 特征向量之和,使用 HDBSCAN 对恶意应用中 RoI 不为空的函数做聚类;对于输入函数,选择最相似(中心距离最小)的簇中的绝大多数标签作为函数标签。
系统架构如图 2 所示,两个功能对应于 ROI detection 和 ROI annotation。
RoI Detection
训练在良性分布上的自编码器,可利用重构误差来识别恶意行为(异常)。例如给定样本\(x\subset\mathbb{R}^m\),计算均方误差\(MSE(x, \hat{x}) = \frac{1}{m}\sum(x^{(i)}-\hat{x}^{(i)})^2\),得到一个标量,再与给定的阈值做比较。
但考虑到 malware 与 goodware 有相似但独特的功能,因此选择识别恶意的区域而非整个样本。MSE 由局部均方误差(LMSE)代替:\(LMSE(x, \hat{x}) = (x^{(i)}-\hat{x}^{(i)})^2\),得到一个向量,再将其中的平方误差逐个与阈值进行比较,大于阈值的块被识别为异常。
In contrast to previous works, which identify an entire sample as being malicious, we identify the malicious regions in each sample.
特征表示
区域由 BB 界定,即 \(m\) 表示 BB 的个数;每个BB的特征用 \(c\) 个特征值表示,因此输入样本 \(x\) 被表示为一个 \(m\times c\) 的矩阵。
具体的,\(m\) 被设定为前 20k 基本块(90% 样本的 BB 数量小于等于该值); \(c\) 为 18,包含 BB 内不同类型 指令/API 的数量、BB 在 CFG 上的结构特征:
-
结构(*2):后继节点个数,介数中心性
对于连通图中的每一对节点,在节点之间至少存在一条最短路径,使得路径通过的边数(对于未加权图)或者边权重的和(对于加权图)最小。节点的中心性是经过该节点的最短路径的数量。
-
加密通常包含很多xor指令,混淆常包含逻辑和位移位操作的结合。
-
端口操作:从源操作数(第二个操作数)指定的 I/O 端口将数据复制到目标操作数(第一个操作数)。
解混淆/解密 常涉及许多 move-related 指令,远程控制逻辑由于要调用更多的内部/外部函数,因此包含更多栈操作相关的指令。
-
directly represent high-level behaviors
inspired from ACFG features:
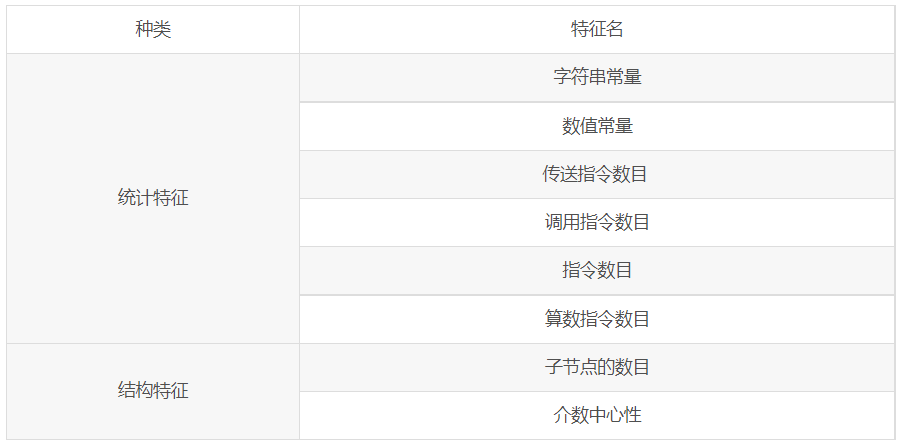
区别:(1) 指令的类别进一步细化(finer-grained),(2) 新增了API类别相关的特征(summarize program behavior);(3) 舍去了与 字符串/数值常量 相关的特征(too easily prone to evasion attacks)。
Of course, given a motivated adversary, any ML model can be attacked and tricked into producing incorrect and unintended outputs. Whilst our features and model are not an exception to this, we argue that they suffice to produce a reliable model and make it difficult enough such that an adversary would have to work extensively to produce misleading input.
RoI Annotation
给定样本 \(x\),DeepReflect 要识别每个函数的行为类别。由于标注所有的函数是不现实的,因此使用聚类分析(cluster analysis),标注少量样本来传播标签。
函数是使用的工具(如 BinaryNinja)在CFG上启发式地静态分析出来的,因此不同反编译器之间可能不一致。
- 聚类特征:\(F\)是样本\(x\)中函数的集合,将每个函数\(f_i\in F\)中包含的RoI记作\(q_i\),则对于\(q_i\neq \emptyset\),函数\(f_i\)的行为特征可表示为\(\frac{1}{\lvert q_i \rvert}\sum q_i\)。将数据集中恶意样本的所有可表示行为的函数提取出来,用于聚类训练。为了将聚类的规模扩大到 500k 个函数,在训练前先使用了 PCA 将维度从 18 降到了 5。
- 聚类模型:选择基于密度的聚类算法 HDBSACN,原因有(1)识别非凸的簇(
K-Means),(2)自动选择最优的簇密度的超参数(DBSCAN)。
系统部署
初始化(Initialization)
(1)输入脱壳后的良性和恶意样本数据集,逐个提取静态特征表示为\(m\times c\)的矩阵,分别表示为\(X_b\)和\(X_m\);
(2)用良性样本的特征\(X_b\)训练自编码器\(M\);
(3)使用\(M\)从恶意样本特征\(X_m\)中提取RoI(\(R_x\)),表示可疑函数的行为特征,得到聚类用的训练数据集\(D\);
(4)使用 PCA 对\(D\)降维并聚类得到\(C\)。
执行(Execution)
输入单个恶意样本,类似初始化的进行(1)和(3),对于样本中的每个函数,从(4)得到的\(C\)中通过质心距离找到最相似的簇,将该簇中占多数的标注赋予函数,返回给恶意应用分析师。
实验评估
五个方面
- Reliability: 在三个恶意样本(rbot, pegasus, carbanark)上标注函数(malicious/benign)作为 ground truth,与三个 baseline 比较 AUC
- Cohesiveness: 随机抽取样本并让恶意应用分析师标注,与 DeepReflect 的结果作比较
- Focus: DeepReflect 返回的结果,使得恶意应用分析师需分析函数数量的减少
- Insight: 不同恶意应用家族之间共享的功能,以及 DeepReflect 处理未知恶意应用家族的能力
- Robustness: 通过混淆、修改恶意应用源码测试逃逸 DeepReflect 的成功率
训练数据集
前提:能使用 Unipacker 成功脱壳,根据文件内容的哈希去重
良性样本:从CENT爬取,包含了 22 个类别,共 23,307 个
恶意样本:VirusTotal上2018年收集的,包含 4,407 个恶意应用家族,36,396 个PE文件
AE 识别异常的可靠性
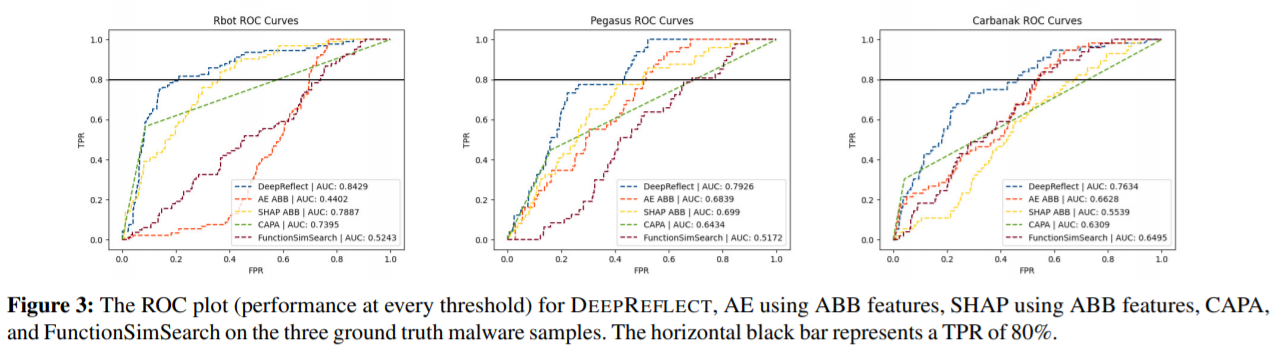
Baseline
-
利用 VGG19 做监督学习,为了模型能收敛,使用去了常量的 ACFG 特征(记作 ABB 特征),预测样本的恶意应用家族,使用 SHAP 可解释机制输出基本块特征重要性,函数重要性由基本块 SHAP 值加和(负值置零);
SHAP (SHapley Additive exPlanation): 观察某一个(组)样本的预测中各个特征对预测结果产生的影响沙普利法定义i加入组织S的边际贡献(marginal contribution):
-
CAPA: FireEye 开发的基于签名的、从二进制文件中识别恶意行为的工具;
(FPR, TPR)是确定的,ROC 曲线是三点连线
-
FunctionSimSearch: Google Project Zero 开发的函数相似性检测工具,比较方法是使用训练数据集中良性样本训练模型,再用三个样本中有 ground truth 的函数查询,取前 1,000 个最相似的函数的相似度绘制 ROC 曲线。
理想状态:恶意函数的相似度远小于良性函数
聚类算法的凝聚力
FPR 选定5%(在ground truth数据集上表现为“TPR/FPR of 40%/5%”)来确定阈值,自编码器\(M\)在 25,206 个恶意样本(\(<\)~36k)中识别出了 593,181 恶意函数。聚类得到了 22,469 个簇,最大的包含了 6,321 个函数,而最小的包含5个,此外还有 59,340 个噪点。
逆向工程师:5 个,有 2-7 年逆向经验。从 25 个有最大 RoI 的恶意应用家族中随机抽取了 177 个函数,使用 MITRE ATT&CK 定义的类别进行标注,手动聚类了 78 个簇,其中每个函数的分析时间在 15-30 分钟。
比较结果中,有 5 个人工分类的簇在 \(C\) 中属于不同的簇,有 8 个不同的在 \(C\) 中被错误的合并;有 89.7% 的函数结果是匹配的。
定位结果的专注度提升
Workload Reduction
| min | max | AVG | |
|---|---|---|---|
| Functions | 1 | 527 | 23.53 |
| 1 | 26,671 | 663.81 | |
| BB inside f | 1 | 134,734 | 96.02 |
| 1 | 22,947 | 16.51 |
不计标题,单数行是hilighted,双数行是total函数的统计数据。其中,BB inside f可反应函数的复杂度
标斜体的数据有问题:highlighted的max怎么会比total大?
False Positives & Prioritization
选阈值时:TPR取40%
| TP | FP | Deepreflect/SHap* | |
|---|---|---|---|
| rbot | 39 | 23 | 0.629/0.487 |
| pegasus | 22 | 80 | 0.229/0.138 |
| carbanark | 8 | 69 | 0.111/0.01 |
*取重构误差排前100的异常component,与SHAP比较precission
False Negatives
| FN | TN | |
|---|---|---|
| rbot | 53 | 325 |
| pegasus | 27 | 407 |
| carbanark | 48 | 2,111 |
Insight
分析了family在簇中的分布:一个簇中的diversity,只有一个样本的family(singleton)中的函数是否能被归类
处理新family的能力:去了4个family后训练得聚类结果\(C1\),与完整训练的结果\(C2\)作比较(1)新的簇会生成(2)部分函数能被归到老的簇中
对混淆的鲁棒性
实验方法:(1)使用Obfuscator-LLVM中的三个技术(及结合)混淆rbot样本得源代码;(2)在恶意样本中加入benign code,会直接影响特征
(1)中有修改control-flow和指令的,没有改API的,所以几乎不影响