
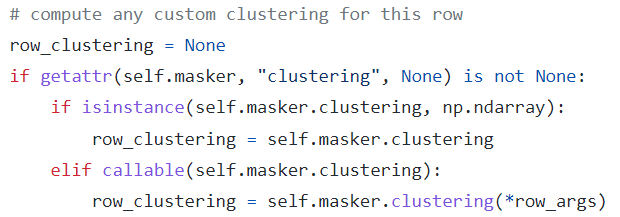
Explainers在explain_row函数中,依据self.masker的clustering属性生成单个样本的masks,该属性可以是固定的np.ndarray,也可以是callable的(每个样本有不同的簇划分方式)。
-
Partition explainer 使用
make_mask(self._clustering)生成self._mask_matrix,传入owen函数

-
Permutation explainer 使用
partition_tree_shuffle(inds, inds_mask, row_clustering)来生成随机排列的masks组合;对于一个permutation而言,masks是一个大小为$2*M+1$的batch,对应于每个mask的非零值数量由$0 \sim M \sim 0$变化,其中$M$表示特征总数。
clustering是一个由 scipy.cluster.hierarchy 定义的 linkage matrix (记作 $Z$,行向量标记为 $Z[i]$)。它是一个$(n-1)$行$4$列的二维数组,其中$n$表示原始样本的个数
- 2-D array (type double) with $n$ rows and $4$ columns
- the first two columns: cluster indices between $[0,2n-1]$ that combined to form cluster $n+i$
- Indices between $[0, n)$: one of the n original observations
- $Z[i, 0]$ and $Z[i, 1]$ are from $[0, i+n-1]$
- the third column: the distance between clusters $Z[i, 0]$ and $Z[i, 1]$
- the fourth column: the number of observations in the newly formed cluster.
以 Text masker 为例
>>> from shap.maskers import Text
>>> text_masker=Text()
>>> s='Hello, world! My name is Yiling He.'
>>> text_masker.tokenizer(s)
{'input_ids': ['Hello', 'world', 'My', 'name', 'is', 'Yiling', 'He'], 'offset_mapping': [(0, 5), (7, 12), (14, 16), (17, 21), (22, 24), (25, 31), (32, 34)]}
>>> text_masker.clustering(s)
array([[ 0. , 1. , 0.28571429, 2. ],
[ 2. , 3. , 0.28571429, 2. ],
[ 4. , 5. , 0.28571429, 2. ],
[ 9. , 6. , 0.42857143, 3. ],
[ 7. , 8. , 0.57142857, 4. ],
[11. , 10. , 1. , 7. ]])
以 Image masker为例
# Image masker
>>> masker_blur=shap.maskers.Image('blur(1,1)', image.shape) # (5,5,3)
>>> masker_blur.mask_value
'blur(1,1)'
>>> masker_blur.clustering.shape
(74, 4)
>>> masker_blur.clustering
array([[ 1., 0., 0., 2.],
[ 4., 3., 0., 2.],
[ 7., 6., 0., 2.],
[ 10., 9., 0., 2.],
[ 13., 12., 0., 2.],
[ 16., 15., 0., 2.],
[ 19., 18., 0., 2.],
[ 22., 21., 0., 2.],
[ 25., 24., 0., 2.],
[ 28., 27., 0., 2.],
[ 31., 30., 0., 2.],
[ 34., 33., 0., 2.],
[ 37., 36., 0., 2.],
[ 40., 39., 0., 2.],
[ 43., 42., 0., 2.],
[ 46., 45., 0., 2.],
[ 49., 48., 0., 2.],
[ 52., 51., 0., 2.],
[ 55., 54., 0., 2.],
[ 58., 57., 0., 2.],
[ 61., 60., 0., 2.],
[ 64., 63., 0., 2.],
[ 67., 66., 0., 2.],
[ 70., 69., 0., 2.],
[ 73., 72., 0., 2.],
[ 2., 75., 0., 3.],
[ 5., 76., 0., 3.],
[ 8., 77., 0., 3.],
[ 11., 78., 0., 3.],
[ 14., 79., 0., 3.],
[ 17., 80., 0., 3.],
[ 20., 81., 0., 3.],
[ 23., 82., 0., 3.],
[ 26., 83., 0., 3.],
[ 29., 84., 0., 3.],
[ 32., 85., 0., 3.],
[ 35., 86., 0., 3.],
[ 38., 87., 0., 3.],
[ 41., 88., 0., 3.],
[ 44., 89., 0., 3.],
[ 47., 90., 0., 3.],
[ 50., 91., 0., 3.],
[ 53., 92., 0., 3.],
[ 56., 93., 0., 3.],
[ 59., 94., 0., 3.],
[ 62., 95., 0., 3.],
[ 65., 96., 0., 3.],
[ 68., 97., 0., 3.],
[ 71., 98., 0., 3.],
[ 74., 99., 0., 3.],
[101., 100., 0., 6.],
[104., 103., 0., 6.],
[107., 102., 0., 6.],
[106., 105., 0., 6.],
[109., 108., 0., 6.],
[111., 110., 0., 6.],
[114., 113., 0., 6.],
[116., 115., 0., 6.],
[119., 118., 0., 6.],
[122., 117., 0., 6.],
[121., 120., 0., 6.],
[124., 123., 0., 6.],
[112., 130., 0., 9.],
[128., 125., 0., 12.],
[129., 126., 0., 12.],
[135., 132., 0., 12.],
[136., 133., 0., 12.],
[127., 138., 0., 18.],
[131., 139., 0., 18.],
[134., 140., 0., 18.],
[137., 142., 0., 27.],
[141., 144., 0., 30.],
[143., 145., 0., 45.],
[146., 147., 0., 75.]])
在 MaskedModel (a utility class that combines a model, a masker object, and a current input)中依照的masker属性
invariants(callable): if the masker supports it, save what positions vary from the background- 与mask的shape相同,通常为全False
- 在
_full_masking_call函数中使用:返回值取反后得self._variants,可支持某些feature始终不变(通过与mask做bitwise and使某位置不被遮盖)
shape(callable/np.ndarray): compute the length of the mask (and hence our length)- 决定了
self._masker_rows和self._masker_cols,其中前者为通常为1,后者决定了单个样本mask的形状(即__call__函数中的full_masks,也是__len__的返回值)
- 决定了
mask_shapes- 会在 explainers 的
explain_row函数最后被调用,包含到返回的结果dict中,并在__call__函数最后依据它来reshape返回的feature attribution values
- 会在 explainers 的