
Contents
Out-of-sample Node Representation Learning for Heterogeneous Graph in Real-time Android Malware Detection

与腾讯安全实验室的合作项目,部署在名为AiDroid的系统中。一作即HinDroid (KDD 2017最佳应用论文)的作者,改进的部分主要是解决了out-of-sample node的问题。
Proposed Method
Feature Extraction
-
Dynamic Behavior Extraction: extract the sequences of API calls in the application framework from runtime executions of Android apps to capture their behaviors.
“TigerEyeing” trojan: connecting to the C&C server in order to fetch the configuration information;
(StartActivity, checkConnect, getPhoneInfo, receiveMsg, sendMsg, finishActivity)
事实上AiDroid并未用到序列信息,仅在对比实验中用了。
-
Relation-based Feature Extraction
-
R1: the app-invoke-API relation
-
R2: the app-exist-IMEI relation
IMEI(International Mobile Equipment Identity,国际移动设备识别码)
-
R3: the app-certify-signature relation
-
R4: the app-associate-affiliation relation
根据package name推测,如”com.tencent.mobileqq”->app: mobileqq, affiliation: tencent.com
-
R5: the IMEI-have-signature relation
-
R6: the IMEI-possess-affiliation relation
-
Heterogeneous Graph Construction
定义1(异构网络):一个异构网络定义为 \(G=(V,E)\) 及其实体类别映射 \(\phi{:} V\rightarrow{A}\) ,关系类别映射 \(\psi{:} E\rightarrow{R}\) ,其中 \(V\) 为实体集合, \(E\) 为关系集合, \(A\) 为实体类别集合, \(R\) 为关系类别集合。其中实体类别个数 \(\lvert A \rvert > 1\) ,关系类别个数 \(\lvert R \rvert > 1\) 。则异构网络定义为 \(\Gamma_{G}=(A,R)\) ,表示为一个由属于 \(A\) 类型的节点以及属于 \(R\) 类型的边组成的图。
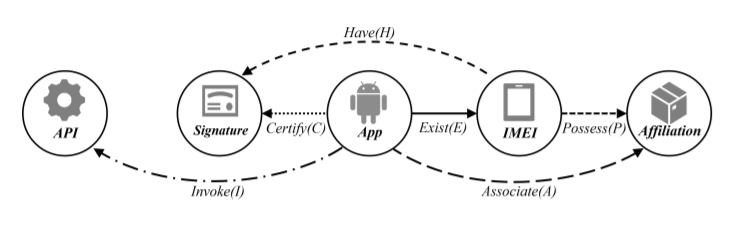
incorporated the domain knowledge from anti-malware experts, designed six meaningful meta-paths to characterize the relatedness over apps at different views
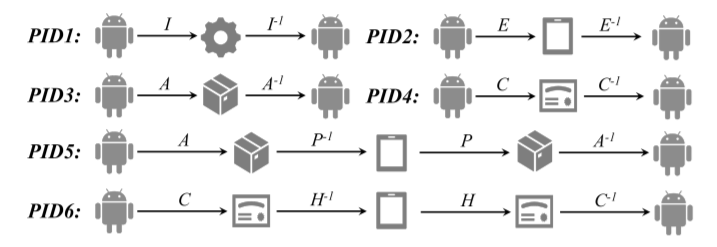
HG-Learning
定义2(异构网络表示学习):给定一个多源异构网络 \(G=(V,E)\) ,其表示学习任务定义为学习一个映射 \(f: V\rightarrow{R^d}\) ,将每个节点映射 \(v\in{V}\) 为一个 \(R^d\) 中的 \(d\) 维向量,并保留节点的结构和语义关系信息。其中 \(d\ll{\lvert V \rvert}\) 。
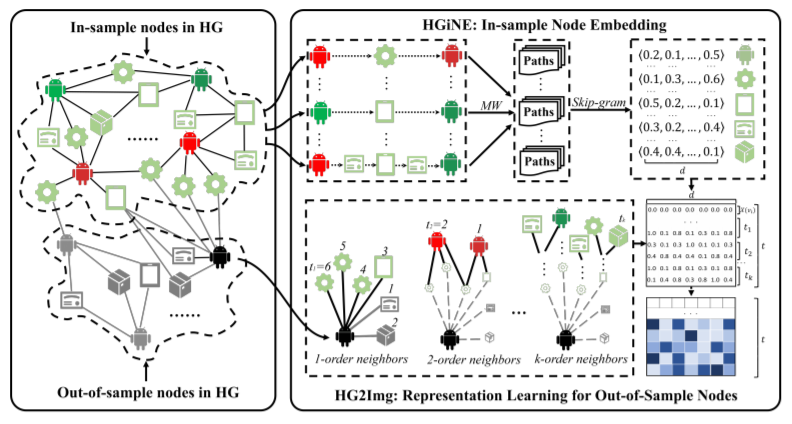
In-sample node embedding (HGiNE)
每一种元路径 \(P_{j}\) 的形式表达为 \(A_1\rightarrow{...}\rightarrow{A_t}\rightarrow{A_{t+1}}\rightarrow{...}\rightarrow{A_l}, A_t\in{A}\) 。则HGiNE下的随机游走策略可以表达为:首先 \(S\) 中从随机选取一个元路径 \(P_{j}\) ,则第i步的转移概率为:
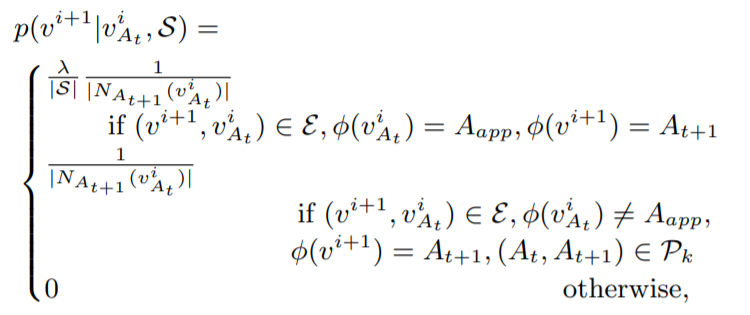
其中, \(N_{A_{t+1}}(v_{A_t}^i)\) 表示节点类型为 \(A_{t+1}\) 的 \(v_{A_t}^i\) 的邻居节点, \(A_{app}\) 表示App节点类别, \(\lambda\) 为 \(S\) 中以 \(A_{app}\rightarrow{A_{t+1}}\) 开头的元路径的个数。文章称这种策略可以将多源异构网络中的语义信息和结构信息更多的保留下来。
-
如果第i步当前的节点是一个app的话,那么下一步的节点必须满足 \(S\) 中存在以 \(A_{app}\rightarrow{A_{t+1}}\) 开头的元路径。
-
如果第i步当前的节点不是一个app的话,那么下一步的节点必须满足 \((A_t,A_{t+1})\in{P_k}\) ,即路径类型必须存在于当前所选的元路径中。
在随机游走生成语料之后,通过skip-gram算法进行节点编码。
Out-of-sample node representation learning (HG2Img)
首先,用BFS(广度优先搜索)找出k度以内的 \(t-1\) 个邻居节点,加上自身编码,一共得到t个d维编码 ( \(t=1+\sum_{1}^{k}t_k\) ),合并为一个 \(t\times{d}\) 维的向量,作为目标节点的编码。
如果这个t节点中存在out-of-sample节点,则该节点的值用0向量替代。
文章推荐 k=2, t=d。
Deep Neural Network Classifier
Training: 在in-sample数据集上,将该 \(t\times{d}\) 维的向量作为CNN的输入,训练一个有监督的CNN
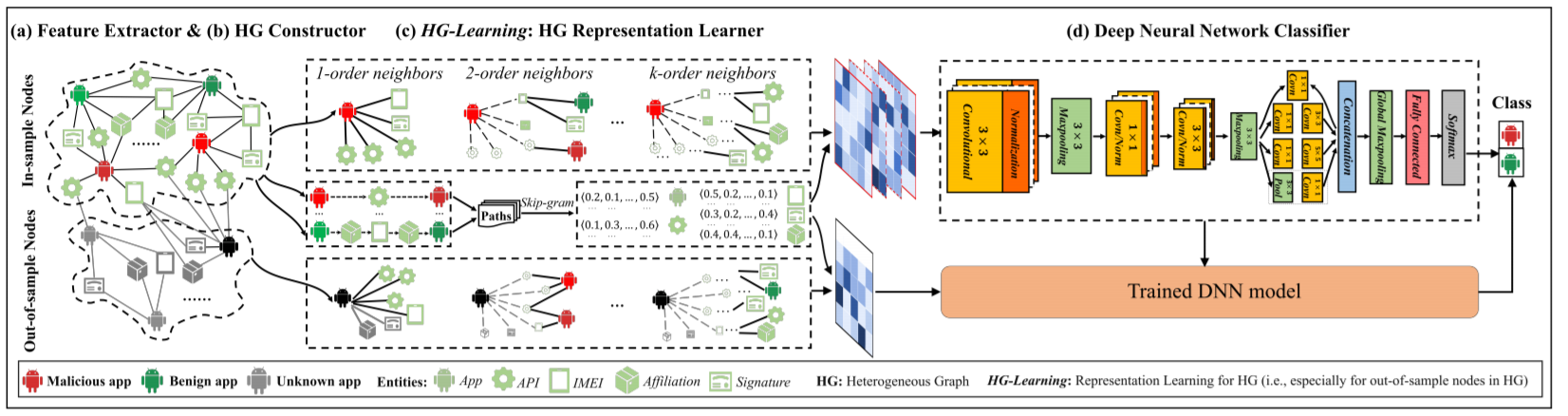
使用CNN原因的猜测:CNN的特性决定了只要out-of-sample的节点的邻居节点大部分是in-sample的,CNN模型的有效性就不会受到大的影响。
Experimental Results
Data Collection
- 来自腾讯安全实验室的190696个app,其中有106912个恶意app和83784个正常app;
- 所构建出的多源异构网络一共286421个节点,新加入的节点包括331个API,70187个设备,8499个证书,16708个app开发商;
- 共计17746个out-of-sample的app作为测试样本,其中4433个app为恶意app。
HG-learning method
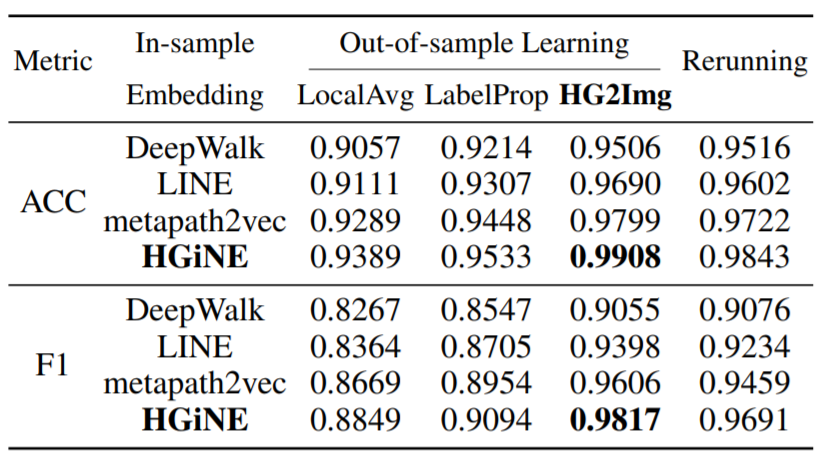
In-sample node embedding (HGiNE)
-
DeepWalk, LINE: 采用了word2vec思想的网络表示算法
异构网络上的随机游走会偏向于某些高度可见的类型的顶点
-
metapath2vec
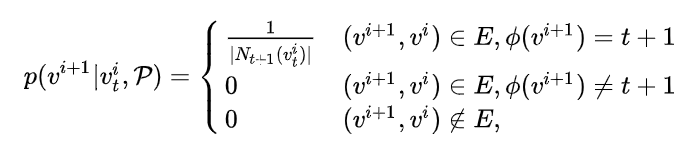
Out-of-sample representation learning (HG2Img)
-
LocalAvg: averaging embeddings of neighboring in-sample nodes
-
LabelProp: LP标签传播算法 [附1]
Zhu, X., and Ghahramani, Z. 2002. Learning from labeled and unlabeled data with label propagation. Technical report, Carnegie Mellon University.
-
Rerunning
Different types of features
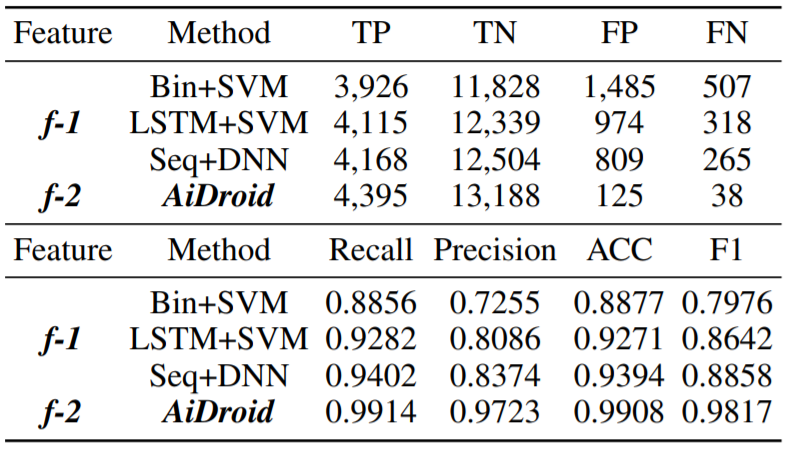
- Behavioral sequence (f-1)
- Bin+SVM: binary (i.e., if an API call is invoked by an app) feature vectors
- LSTM+SVM
- Seq+DNN: train proposed DNN based on the extracted API call sequences
- HG-based (f-2)
[附1] LP标签传播算法
\(P_{ij}\) 是一个 \(N\times{N}\) 的矩阵,表示从节点i转移到节点j的概率,由边的权重计算 \(P_{ij}=\frac{w_{ij}}{\sum_{k=1}^{n}w_{ik}}\) 。
假设有 \(C\) 个类和 \(L\) 个labeled样本,我们定义一个 \(L\times{C}\) 的label矩阵 \(Y_L\) ,第i行表示第i个样本的标签指示向量,即如果第i个样本的类别是j,那么该行的第j个元素为1,其他为0。
同样,给 \(U\) 个unlabeled样本一个 \(U\times{C}\) 的label矩阵 \(Y_U\) 。合并得到一个 \(N\times{C}\) 的soft label矩阵 \(F=[Y_L;Y_U]\) 。soft label的意思是,保留样本i属于每个类别的概率,而不是互斥性的。
-
执行传播:F=PF
将矩阵P和矩阵F相乘,这一步,每个节点都将自己的label以P确定的概率传播给其他节点。如果两个节点越相似(在欧式空间中距离越近),那么对方的label就越容易被自己的label赋予,就是更容易拉帮结派。
-
重置F中labeled样本的标签:FL=YL
因为labeled数据的label是事先确定的,它不能被带跑,所以每次传播完,它都得回归它本来的label。随着labeled数据不断的将自己的label传播出去,最后的类边界会穿越高密度区域,而停留在低密度的间隔中。相当于每个不同类别的labeled样本划分了势力范围。
-
重复步骤 (1) 和 (2) 直到F收敛。
参考链接: